
From Hype to Reality: Testing OpenAI’s o1 in a Competitive Setting
In my previous article, I discuss the need for AI benchmarks to assess real world performance and how this year’s HackerCup competition is providing a great opportunity for this.
Well looks like OpenAI released o1-preview and o1-mini just in time 🎉
The new chain of thought (CoT) models, released on September 12th, claim to feature improved reasoning abilities across a variety of subject matters, and have some very nice cherry-picked examples in the technical report . So why not put it to a test? And what better way than the HackerCup AI competition.
I didn’t have much time to prep before the practice round, so I tried integrating the new model into the existing AutoGen flow. The o1-preview is significantly slower than o1-mini and received lower score on the Codeforces competition, so I stuck with mini.
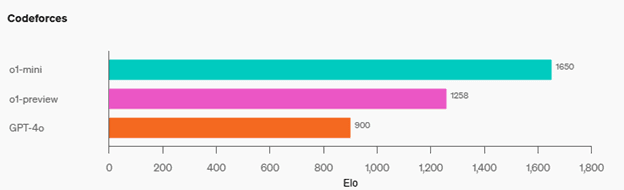
The OpenAI examples shows a comparison of models running the same prompt:

My modified workflow included using AutoGen agents to generalize the problem for the CoT model (GPT-o1-mini) to code. In retrospect, this is not necessary as o1-mini can do this iteration itself. With this approach, I was able to answer 1/5 practice round questions correctly. Not super promising ☹
It turns out this competition will be really challenging for AI due to the speed and accuracy needed. Staying under the 6-minute time limit to complete all problems is a feat, especially using the more generalized model o1-preview. The o1-mini model averages around 40-50 seconds per solution with our current workflow which includes 3 rounds of iteration. Much faster than the nearly 8 minutes it takes o1-preview to generate the results.
So how does o1-mini, o1-preview, and GPT-4o stack up on this coding challenge?

Results may differ based on prompting strategies. With round 1 of the competition in just a few days, we will see if AI can compete. 🤖
References: